
If you're thinking of creating a scripting language for your application, reading this article could save your life.
Well, maybe not your entire life, but at least a lot of time. And when you get right down to it, isn't time just a small piece of your life?
Configuration is a key feature that differentiates real applications from student projects. Making an application configurable sounds simple because it mirrors good programming practice: hard code nothing, make everything flexible. In practice it turns out to be a little tricky, so we're going to take a look at what makes it challenging and what we can do to avoid getting into serious trouble.
Naïve Configuration
Configurability starts with switches and options, but before long rules, macros, and business logic start creeping in. Try to deal with the demands for ever increasing flexibility in an ad-hoc manner and you'll end up maintaining an arcane semi-language with combinatorial interactions that infect your entire application and reduce development to a snail's pace.
And getting out of a mess may not be so easy. You see, there's a real difference between soft-coding and configuration that you expose to your users: backwards compatibility. Users want their old configuration files to work as-is when they upgrade. While dealing with older configuration files should be easy in theory, in practice it constrains you to
- continually add complexity to the format and never simplify anything
- support multiple versions of your configuration engine
- or write conversions to update old configuration files.
None of these are impossible, just expensive. But it sounds like it would be better to:
- Provide a cleanly extensible framework
- decouple the configuration from the rest of the application
Scripting Languages to the Rescue!
It sounds like it's time to bring in a full fledged scripting language.
For many applications, the need for a scripting language is so obvious that we can justify creating our own language or embedding one of the large, powerful scripting languages. But for most applications the case is less clear cut. Faced with a limited scope, we turn to macros and the like.
Don't do this.
The ad-hoc options are swamps and quagmires. However cheap it seems now, supporting these systems is murder. The completeness of a full blown language will cover cases you couldn't even imagine when you started, while the ad-hoc solutions will cause problems likewise beyond your wildest imagination. In the end, it's a lot more fun to do things well then the live with the consequences of doing them badly.
But we're still facing that limited scope. We don't want to go overboard, but we do want to make sure the language we choose really will be extensible and complete enough to cover us for the foreseeable future. Which brings us to the crux of the article:
What is the minimal interpreted scripting language?
Now, that's going to need some definitions:
-
minimalin terms of both footprint and learning curve. - a programming `language' must have a certain set of constructs: if-then-else, looping, function definitions, and variable binding or their equivalents.
-
interpretedmeans run-time parsing and evaluation plus automatic memory management. We want to buy simplicity with CPU cycles. -
scriptinteracts with some larger environment (our application) exposing lower level data and making lower level calls through a simple interface.
Before we go any further, I want to make it clear that I'm not recommending a minimal language. I'm saying that you should absolutely, positively, not implement anything less than it. Of course a few simple switches are fine, so here's a rule-of-thumb for when to switch:
When we need to support
if-then-else, it's time to implement a complete language.
The Straw Man Language
The physicist Feynman said, "what I cannot create I do not understand." To look for the minimum interpreted scripting language, we'll attempt to create it. Now, any standard language is far superior to a custom one, simply by virtue of being standard. So we won't actually be trying to create a working language, but just scribbling out a prototype. We'll work in Python, despite the inherit silliness of implementing a scripting language in a scripting language. If all goes well, the lessons learned will point us towards a better, standard language. I call my little Python prototype "straw man."
Plan to throw one away; you will, anyhow. - Frederick Brooks
To AST or not to AST
A language needs a parser, but the responsibility of the parser is a design decision. We can execute as we parse, or we can simply build an Abstract Syntax Tree for later evaluation. As a quick reminder, an AST is a tree that represents the structure of a program:
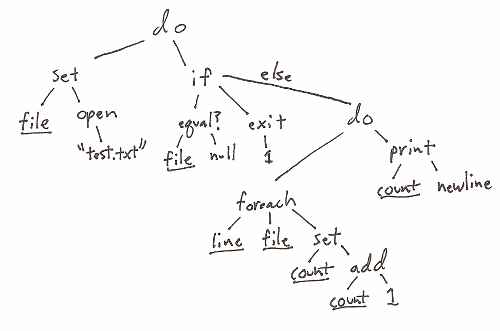
The most unusual thing about an AST (from a programmer's perspective) is that it makes a distinction between symbols and values. if is a symbol, while "if" would be a value. There are really two kinds of nodes in an AST tree: symbol nodes and value nodes. That makes it a subtly different (and more interesting) structure than a value-only tree.
If we wanted to execute the instructions as we parsed them, a Stack-based language would be the way to go. That doesn't even limit us to prefix notation thanks to Dijkstra's shunting yard algorithm and would eliminate a layer.
However, it's not a layer we want to eliminate. Executing during parsing means implementing the language within the events of a parser, which gets messy for anything more complex than a calculator. Another disadvantage is that we may not detect a syntax error, such as an unclosed parenthesis, until much of the program has been evaluated. This can lead to wild side effects, which is unacceptable: we don't want the user to have to restart the application because of a typo in a script!
On the other hand, The AST provides long-term maintainability by decoupling the run-time engine from mere syntax, and we'll see below why an AST is a nice thing to have around.So we'll go with a two stage interpreter: one pass to build the AST, and a second to run it. That's a safe, well-explored strategy.
Mere Syntax
I'm going to side-step the problem of using a real parser and use a simple stack-based parser, which isn't classy but quite easy to implement. We'll break tokens on whitespace. Following the AST model closely, the parser expects that any symbol will be followed by an optional list of symbols enclosed in parenthesizes:
set(count add(count 1))
So, for my straw man language, I'm basically going with a prefix notation that closely resembles the common function call. This part of the code isn't interesting, but you can read it in the source if you like. I've also introduced a touch of syntactic sugar: a do() block may written as { }. Below we'll see { } does what we expect, and simply evaluates each expression in it.
First Look
Here's a real example of an straw man program:
set(x 17);
set(y 8);
print( "x=" x "y=" y);
print( "changing x...");
set(x 9);
print( "x=" x "y=" y);
if( gt(x y)
{ print("x is greater than y."); set(z x); }
{ print("x is not greater than y."); set(z y); }
);
print( "greatest of x and y:" z );
print( "total of x and y:" add( x y) );
and its output:
x= 17 y= 8
changing x...
x= 9 y= 8
x is greater than y.
greatest of x and y: 9
total of x and y: 17
All of the 'functions' (set, print, gt, add) in this program are primitives, that is, they are identified and computed by the core interpreter. The only really complex primitive is set(), the assignment operator. To make this work, we have to have to carry around the concept of an environment, a mapping from variables to values. This adds complexity to the system, but without assignment the language would be unusable. (I know this because it was hard to write test cases before implementing set().) We'll add stuff like user defined functions below, but there are plenty of lessons to be learned from implementing these few primitives, so I'll cover that first.
Primitives
The first lesson is not to evaluate everything: the else clause of the if never get's hit, and we don't evaluate the x in set(x 17) but instead treat it as a symbol. It's hard to imagine how we'd implement things like conditionals and loops if we can't control which subnodes get evaluated, which get treated as symbols, and which are simply ignored.
This is interesting because it suggests that an operator to suppress evaluation would be useful. If an AST node isn't evaluated, then what is it? Well, I suppose it would be data:
set(tree data("Friends" ("John" "Jill") "Pets" ("Spot" "Tiger") ))
print(tree)
foreach(branch tree {
print(val(branch) ":")
foreach(leaf branch {
print(" " leaf)
})
})
Here, the variable tree is being bound to this AST:
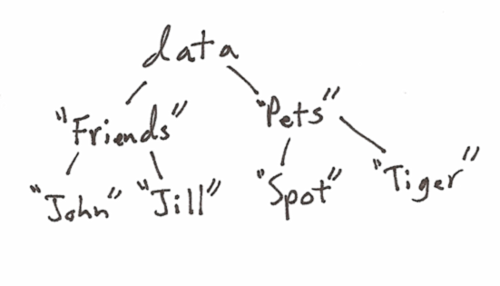
When a data node is evaluated, it simply returns itself. In this sense, it's a stopping point for evaluation, and the effect is that it acts like an array or tree. Here's the output of the above:
data(Friends(John Jill) Pets(Spot Tiger))
Friends :
John
Jill
Pets :
Spot
Tiger
I said before that an AST was a handy thing to have around. Now we see why: all I have to do is denote that a given subtree is data, not code, and I get arrays (actually, trees, since we can nest them) for free. This certainly sounds minimal.
Now recall that I made the point that an AST is richer than a tree in that it contains both symbols or values. In the above example, we only used values inside the data structure, but we could use symbols too. In fact, we can have straw man code inside the data structure. This sounds promising, so lets explore it.
Quotes
For data to be meaningful as code, we have to be able to run it. We introduce a quote primitive, that returns it's first subnode when evaluated. (Actually, I called it something else at first, but changed it's name to quote for reasons we'll see below.) Notice the difference between data and quote; data is a stopping point, while quote is merely a delay. Repeatedly evaluating data always yields itself, but a quote is stripped off by each evaluation. To force repeated evaluation, I've also introduced the eval primitive:
set(code quote(print ("hello world!")) )
print ("code = '" code "'")
print ("when I evaluate the code, I should see 'hello world' as a side effect:")
eval(code)
and the output:
code = ' print(hello world!) '
when I evaluate the code, I should see 'hello world' as a side effect:
hello world!
(See the source for more complex examples.) So now we've completed the loop: we can treat code as data, and data as code, and we have a unifying syntax for both. I've argued that what we need to avoid the ad-hoc swap is a complete system, and we certainly seem to be heading in that direction; in fact we seem to be getting everything practically for free!
Finally, Functions!
The one thing we haven't built at this point is the universal concept of a user-defined function. Just to wrap up the loose threads, I'll go over that briefly here. However, the prototype is already complete enough to make it clear what the minimal interpreted scripting language is, so you may just want to skip on down to the next section.
We need two things before users can write their own functions:
- a primitive that binds a list of parameters to code
- interpreter functionality that calls a function when it gets hit.
The primitive is traditionally called lambda, and it simply returns an AST with a function node on top and the parameter symbols and code as subnodes. The actual work gets done later, when the function node is evaluated. Then the interpreter creates a new environment for the function (binding the arguments of the function call the parameter symbols) and evaluates the function code.
Since it's all in the source, let's just throw up a quick example for user-defined functions and move on:
set(f lambda ( quote(x) add(x 1) ))
print( f(2))
set(metric lambda ( quote(x y) add(product(x x) product(y y)) ) )
print( metric(5 10) )
print( metric(3 4) )
Output:
3
125
25
Enlightenment
The critical decision was to re-use the structure of the code as a data structure. If two concepts are similar enough, you can halve your work by combining them. (For example, Java recognized that a class is essentially the same thing as a program and unified the two.) Things seem to work out nicely and a lot of functionality comes along for free.
The standard language that has this property is LISP. In fact, LISP uses an even simpler data structure to describe both data and code. I used an AST node that was the combination of a value and list of subnodes:
LISP instead has the cons, which is simple a pair of pointers car and cdr. A list in LISP is a linked list: each element is a cons, cdr points to the next cons, and car points to the value. This can in particular duplicate my AST data structure, but lists in LISPs are easier to work with (for example, you join two lists by setting the last element of one to point to the first element of the other) and the cons is a flexible datatype that can be used to build far more than lists.
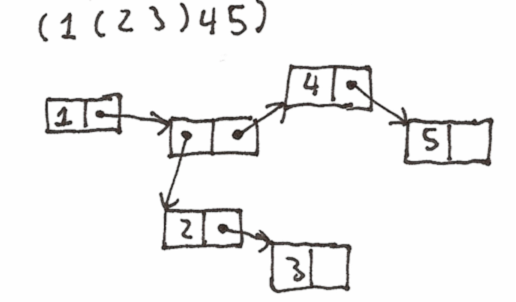
As for functions, we saw that simply by providing control over the evaluations of arguments allowed us to define control structures very easily. LISP lets you do this too, with macros. The evaulation of a macro is pushed to the preprocessor, but the syntax is familiar.
LISP enjoys all the advantages of the straw man language, but has a more mature design, standard libraries, and plenty of educational material. So we conclude that LISP is the minimal interpreted scripting language.
Sliced Bread?
Note that it's not LISP's theoretical strengths that lead us to it, but entirely practical considerations. Script tends is generally very basic; we don't need (or even particularly want) support for symbolic manipulation or tail-end recursion. LISP isn't the greatest language ever (although I'm sure some would disagree), but it is seems to be the smallest. To recap the argument:
- We want it to be interpreted, and a well-designed interpreted language will have a data structure that represents the shape of the program.
- We can avoid special programming for arrays and other data structures by exposing the internal structure as a data structure in the language itself.
- And that makes it very easy to treat data as code, which gives us functions for free.
This design reduces complexity by perhaps a factor of three, and that's probably unbeatable. In retrospect, it isn't terribly surprising. In the early days of programming, a small footprint wasn't a feature: it was a requirement. LISP has been successfully automating applications like Emacs and AutoCAD for many decades now. Unsurprisingly, I'm not the first one to think this way:
Greenspun's Tenth Rule of Programming: "Any sufficiently complicated C or Fortran program contains an ad-hoc, informally-specified bug-ridden slow implementation of half of Common Lisp."
I'm sure the LISP or Scheme communities are already aware of this, but their focus is on LISP's functional and symbol manipulation abilities, not the practical advantage of LISP's elegant design, BOCTAOE. I'd known a little about LISP (otherwise I wouldn't have recognized the similarities to straw man) but thought of it a language that expressed things in an alien, non-intuitive way for the purposes of supporting arcane meta-programming. I took a less biased look at LISP while writing this article, and it's clear even from McCarthy's original article that simplicity is a major goal.
Now, I'm not an expert in LISP, which makes me perfectly qualified to judge LISP's ease-of-use. It's epsilon. LISP is usable in the sense that it covers all the bases, but it's syntax is a little alien.
I can't recommend exposing non-programmers to LISP's syntax directly, but one advantage of LISP's extremely regular syntax is that it is trivial to machine generate. We might consider exposing a subset of the functionality in user-friendly language, for example. Or perhaps a constrained GUI rule builder, like Outlook's rules. That's less work than creating your own language, you hit the ground running with a fully functional system, programmers can still get their hands dirty, and if you're lucky you might end up with a great library of community-submitted scripts.
I haven't done any research into the different dialects of LISP, but from what I've read, GNU Guile is a LISP dialect specifically designed as an embedded C library (haven't tried it, though.)
Now, I'm not recommending Guile or LISP specifically. We should take care to avoid the ad-hoc configuration swamp, and LISP defines one edge of that swamp:
We should also consider the many alternative lightweight scripting languages, such as Io or Lua. You may even be able to afford Python. And I don't want to deter you from sticking to the other side of the swamp, either: many applications provide an excellent, highly polished user experience by locking down configuration options and concentrating on common use cases. Here are good places to start on each side:
- Oran Looney May 20th 2007
Thanks for reading. This blog is in "archive" mode and comments and RSS feed are disabled. We appologize for the inconvenience.